The Complete Ransomware Response Guide
Ransomware Infection
Ransomware is a type of malware that encrypts files on a device, leaving those files and the systems that rely on them inoperable. The decryption is then requested in exchange for a ransom by malicious actors. Ransomware criminals frequently employ the threat of selling or disclosing sensitive data or authentication credentials if the ransom is not paid.
Ransomware can spread through networks (that are not setup securely), harmful links and attachments in phishing emails, or through downloading a fake software update. These actions enable threat actors to break into the victim’s network, move around inside it, and eventually release the ransomware payload, enabling extortion. Victims of ransomware have three choices after an infection: pay the ransom, try to remove the malware, or reset the device.
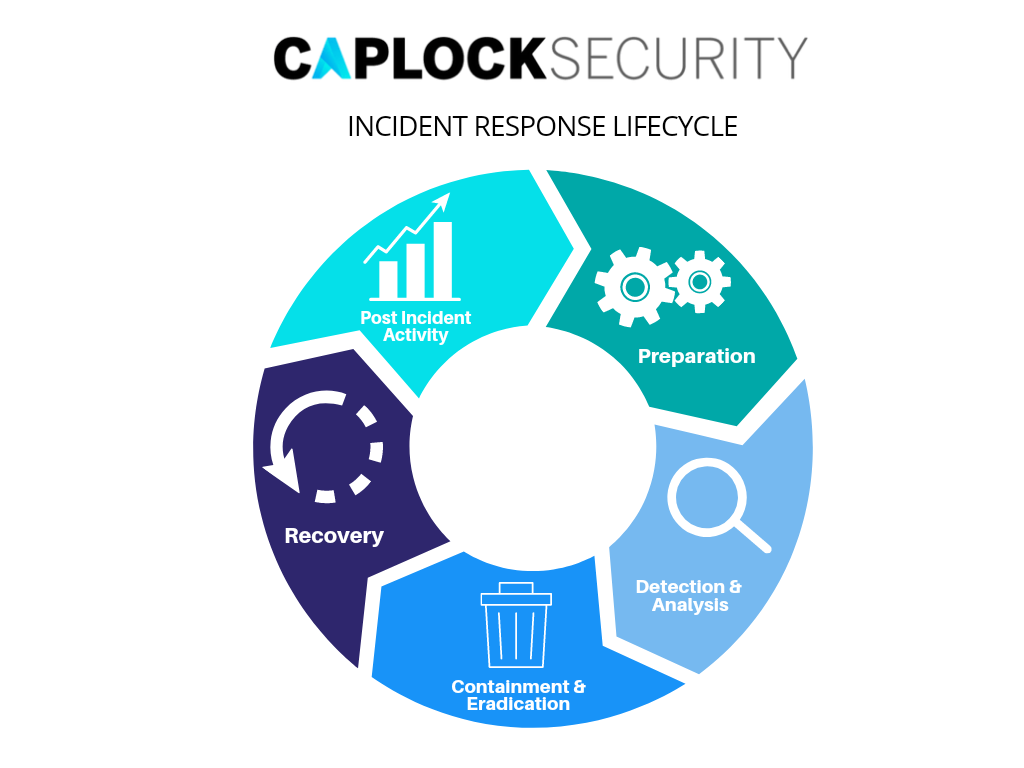
Incident Response Lifecycle
There are various stages in the incident response process. In the initial stage, an incident response team must be formed, trained, and equipped with the appropriate materials. By choosing and putting into place a set of controls based on the findings of risk assessments, the organization makes an additional effort during preparation to reduce the number of events that will occur. However, after safeguards are put in place, residual risk will unavoidably continue.
Therefore, detection of security breaches is required to inform the organization whenever occurrences take place. Depending on the incident’s intensity, the organization can lessen its effects by containing it and eventually rebuilding from it. After the incident has been appropriately controlled, the organization publishes a report that describes the incident’s cause, cost, and recommends preventative measures. In-depth descriptions of the preparation, detection, analysis, containment, eradication, recovery, and post-incident activity phases are provided in this guide.
Preparation & prevention
It is crucial to keep the number of events at a manageable level in order to safeguard the organization’s operations. Higher numbers of incidents could occur and overwhelm the incident response team if security controls are insufficient. Slow and partial reactions might result from this, which has a greater detrimental effect on the business (e.g., more extensive damage, prolonged service interruptions, and data unavailability). Even though they are typically not in charge of protecting resources, incident response teams can help promote safety protocols. An incident response team may be able to spot issues that the company is otherwise unaware of; by spotting gaps in training and risk assessment, the team can be immensely helpful.
- Risk Assessments
System and application risk assessments should be conducted periodically to identify what combinations of threats and weaknesses present hazards. Understanding the relevant threats, particularly those that are organization-specific, should be included. Prioritizing each risk will help to reduce it, transfer it, or accept it until a manageable total level of risk is reached. Periodic risk assessments have another advantage in that they help staff focus on monitoring and response efforts for important resources by defining them.
Host Protection
It is recommended that all hosts use standard configurations for proper fortification. The principle of least privilege, which states that users should only be given the privileges necessary to carry out their allowed responsibilities, should be followed when configuring hosts, in addition to keeping them all properly patched. Auditing should be enabled on hosts, and they should record critical security-related events. Continuous monitoring of host security and configurations is necessary. To help with reliably and effectively protecting hosts, several organizations employ Security Content Automation Protocol (SCAP) defined operating system and application setup checklists.Network Safety
The network perimeter should be configured to deny all activity that is not expressly permitted. All access points, such as virtual private networks (VPNs) and direct connections to other companies, must be secured as part of this.Malware Avoidance
Throughout the organization, malware detection and prevention software should be installed. At the host level (such as server and workstation operating systems), the application server level (such as email servers, web proxies), and the application client level, malware protection should be implemented (e.g., email clients, instant messaging clients).- User education and awareness
Users should be made aware of the rules and guidelines for proper usage of the systems, networks, and software. Users should also be informed of any relevant lessons from prior occurrences so they may understand how their actions might impact the company. The number of incidents should decrease as user knowledge of issues increases. IT personnel ought to receive training so they can maintain networks, systems, and applications in line with the company’s security standards.
Detection
Attack Vectors
It is impossible to create step-by-step guidelines for dealing with every situation because there are endless ways in which they can happen. Organizations should focus on being ready to address incidents that involve frequent attack vectors, even if they should be generally prepared to handle any occurrence. Different reaction plans are required for various incident types. The attack vectors described below are essentially common techniques of attack that can be used as a foundation for establishing more precise handling processes.
- External/Removable Media: An attack executed from removable media or a peripheral device—for
example, malicious code spreading onto a system from an infected USB flash drive. - Attrition: An attack that employs brute force methods to compromise, degrade, or destroy systems,
networks, or services (e.g., a DDoS intended to impair or deny access to a service or application; a
brute force attack against an authentication mechanism, such as passwords, CAPTCHAS, or digital
signatures). - Web: An attack executed from a website or web-based application—for example, a cross-site
scripting attack used to steal credentials or a redirect to a site that exploits a browser vulnerability and
installs malware. - Email: An attack executed via an email message or attachment—for example, exploit code disguised
as an attached document or a link to a malicious website in the body of an email message. - Impersonation: An attack involving replacement of something benign with something malicious—
for example, spoofing, man in the middle attacks, rogue wireless access points, and SQL injection
attacks all involve impersonation. - Improper Usage: Any incident resulting from violation of an organization’s acceptable usage
policies by an authorized user, excluding the above categories; for example, a user installs file sharing
software, leading to the loss of sensitive data; or a user performs illegal activities on a system.
Precursors and indicators
These are the two different types of incident signs. Precursors are indications that an incident could happen in the future. An indicator is a sign that an occurrence may have happened or may be happening right now. The majority of attacks lack any identifiable or discernible predecessors from the viewpoint of the target. If precursors are found, the company may be able to change its security posture to protect a target from attack and maybe avert the crisis. The organization could, at the very least, keep a closer eye on actions affecting the target.
Examples of precursors:
- Web server log entries that show the usage of a vulnerability scanner
- An announcement of a new exploit that targets a vulnerability in the organization’s mail server
- A threat from a group stating that the group will attack the organization.
Examples of indicators:
- A network intrusion detection sensor alerts when a buffer overflow attempt occurs against a database.
- Antivirus software alerts when it detects that a host is infected with malware.
- A system administrator sees a filename with unusual characters.
- A host records an auditing configuration change in its log.
- An application logs multiple failed login attempts from an unfamiliar remote system.
- An email administrator sees a large number of bounced emails with suspicious content.
- A network administrator notices an unusual deviation from typical network traffic flows.
Analysis
A predetermined process should be followed by the incident response team as they work fast to analyze and validate each incident. Each step should be documented. When they believe an incident has occurred, the team should conduct an initial investigation to determine the event’s scope, including which networks, systems, or applications are affected, who or what caused the problem, and how the incident is happening (e.g., what tools or attack methods are being used, what vulnerabilities are being exploited). The preliminary study ought to yield sufficient details to enable the team to set priorities for later tasks like incident containment and a more thorough examination of its consequences. A few crucial recommendations for incident response teams are given below.
Profiling networks and systems
By assessing the expected activity’s parameters, deviations from it can be more quickly detected. Profiling examples include running file integrity checking software on hosts to generate checksums for important files and tracking network bandwidth utilization to identify average and peak usage rates over different hours and days.
Perform Event Correlation
Several logs that each contain a different sort of data may contain evidence of an occurrence; for example, a firewall log may have the source IP address that was utilized, whereas an application log may provide a username. An assault against a specific host may have been detected by a network IDPS, but the attack’s outcome may not have been known. To find out that information, the analyst might have to look through the host’s logs. It can be quite helpful to correlate occurrences from many indicator sources to confirm whether a specific incident actually took place.
Create a log retention policy
There are many areas where information about an incident may be logged, including the firewall, IDPS, and application logs. Older log entries may reveal reconnaissance activities or earlier instances of similar assaults, thus it may be very helpful to create and implement a log retention policy that specifies how long log data should be kept. The fact that accidents might not be detected for days, weeks, or even months is another justification for keeping logs.
Containment
The main goals of the containment stage are to control the harm, stop further damage, and preserve data for future analysis or potential use in legal procedures. Short-term containment of ransomware often takes place concurrently with the attack’s detection.
- Disconnect all infected or questionable devices from the network, if it hasn’t already been done.
- It is best to keep devices connected but powered on. The ransomware unlock codes sometimes stay resident in memory and can be used to quickly restore the device.
- It could be necessary to examine forensic photos of the impacted devices to determine the attack’s primary cause. Try to gather them in the most pristine (unaltered) condition you can.
- Take a picture of virtual systems, and make sure it can’t be unintentionally removed. If possible, incorporate both the data at rest and the memory state.
- A copy of the physical drive is often needed for physical systems. An offline clone is acceptable in the event that employing a forensics tool is not feasible. Ideally, this would be acquired in a running state with a forensics tool.
- Rebuild the device with a new drive, but if at all feasible, keep the original hard disc.
- Assemble and evaluate evidence from additional sources. These could consist of remotely gathered system logs or network device logs (firewalls, IDS, etc.).
Eradication
Eradication involves genuinely getting rid of malware or negating the other tactics attackers have used to infiltrate and keep a foothold in compromised systems. In this phase , systems are again restored, and the precise deadlines and incident scope are finalized.
Create a formal timeline of the occurrence that includes all relevant information. You should have enough data to answer the following questions:
- What accounts were updated, accessed, or created, as well as who accessed the systems?
- What alterations did the attackers make to the systems?
- What harmful or other types of code did the attackers install or use?
- What information did the attackers access, alter, or steal?
Rebuild and repair the systems to get them ready to go back online once the full timing and specifics of the occurrence are understood. It is ideal to never put infiltrated systems back into use because there is always a potential that some trace of the attackers’ presence may remain and compromise the systems. The optimum procedure is to completely patch all software on replacement systems that are built from scratch. It is unnecessary to hold off on commencing this process until the study is over if the replacement systems will be brand-new from the ground up. Starting again is only permitted in situations when it is known exactly when a compromise occurred and a backup that was known to be clean at the time can be utilized instead.
Recovery
During recovery, administrators return systems to their pre-incident state, ensure that they are operating normally, and (if necessary) fix vulnerabilities to prevent future occurrences. Systems may need to be rebuilt from scratch, restored from clean backups, replaced with fresh copies of corrupted files, patched, passwords changed, and network perimeter security tightened as part of recovery (e.g., firewall rulesets, boundary router access control lists).
Higher degrees of network monitoring or system logging are frequently included in the recovery procedure. Once a resource has been successfully assaulted, it is frequently targeted again or other organizational resources are attacked similarly.
Restoring from known good backups is the quickest and easiest way to recover from a ransomware attack. However, it is not enough to only replace the damaged file; the attack’s primary cause must also be addressed. The possibility of re-compromise will be reduced as a result, and the likelihood of the same attack vector being successful will be reduced as well.
To help prevent such occurrences in the future, learning from one incident is essential. The aim of improvement is to finish any unfinished documentation and identify areas where processes and controls can be strengthened to reduce the likelihood of future occurrences that are similar to this one.
Post Incident Activity
Using collected incident data
The characteristics of an event may reveal systemic security flaws and threats as well as shifts in occurrence patterns. This information can be incorporated once more into the risk assessment procedure, which will ultimately result in the choice and application of additional controls. Measuring the effectiveness of the incident response team is a useful application of the data. If incident data is correctly gathered and archived, it should offer a number of indicators of the performance (or at the very least, the actions) of the incident response team. Additionally, incident data can be gathered to see if a change in the team’s performance results in a change in incident response capabilities (e.g., improvements in efficiency, reductions in costs).
Conclusion
Ransomware attacks can come in a wide range of shapes and sizes. The types of ransomware used are greatly influenced by the attack vector. When determining the size and extent of the attack, always consider what is at risk or what data could be deleted or made public. No matter what type of ransomware is used, effectively adopting cybersecurity measures and storing data in advance can significantly lower the intensity of an assault.
In accordance with your business continuity plan, you should take immediate action to preserve your company’s essential operations. Businesses should regularly test their backup plans, disaster recovery plans, and contingency planning methods.
Prevention is better than cure. Do not make the costly mistake of ignoring the cybersecurity aspect of your organization. Caplock Security provides all the solutions needed to simplify your security implementation without impacting performance, enables a unified approach for streamlined operations, and prepares you to scale for business growth.